КАК В EXCEL ОСТАВИТЬ ТОЛЬКО УНИКАЛЬНЫЕ ЗНАЧЕНИЯ
Чтобы в Excel оставить только уникальные значения, можно воспользоваться фильтрами или функцией удаления дубликатов. Рассмотрим оба метода.
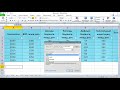
1. Использование фильтров:
1.1. Выделите столбец с данными, в котором нужно оставить только уникальные значения.
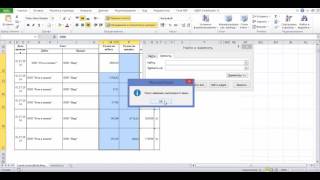
1.2. Перейдите на вкладку "Данные" и в разделе "Сортировка и фильтрация" выберите "Дополнительный фильтр".
1.3. В открывшемся окне выберите "Уникальные записи" и нажмите "OK".
2. Использование функции удаления дубликатов:
2.1. Выделите столбец с данными, в котором нужно оставить только уникальные значения.
2.2. Перейдите на вкладку "Данные" и в разделе "Инструменты" выберите "Удаление дубликатов".
2.3. В появившемся окне оставьте только те столбцы, по которым нужно проверять уникальность записей, и нажмите "OK".
Теперь у вас останутся только уникальные значения в выбранном столбце. Эти методы позволяют очистить данные от повторяющихся значений, облегчая анализ и обработку информации в Excel.
Повторяющиеся значения в Excel: найти, выделить и удалить дубликаты
Повторяющиеся значения в Excel — найти, выделить или удалить дубликаты в Excel
Трюк Excel 25. Список уникальных значений
ФУНКЦИЯ ПСТР+ПОИСК В MICROSOFT EXCEL
Excel. Подсчёт уникальных значений. Подсчёт повторяющихся значений.
Как создать выпадающий список в excel. Самый простой способ
Количество уникальных значений в Excel
8 инструментов в Excel, которыми каждый должен уметь пользоваться
Повторяющиеся значения в Excel
Вам также может понравиться: