EXCEL СОДЕРЖИТ ЛИ ЯЧЕЙКА ЧАСТЬ ТЕКСТА
Excel - популярное программное обеспечение для работы с электронными таблицами, разработанное компанией Microsoft. Одной из возможностей Excel является наличие текста в ячейке, а также возможность извлечения части текста из ячейки.
При работе в Excel вы можете вводить текст в ячейки, и он будет сохраняться в виде строки данных. Вы также можете использовать формулы и функции в Excel для работы с текстом. Например, с помощью функции LEFT() или RIGHT() вы можете извлекать определенное количество символов из начала или конца ячейки.
Если вам необходимо проверить, содержит ли ячейка определенную часть текста, вы можете использовать функцию SEARCH(). Она позволяет найти позицию первого вхождения указанного текста в ячейке. Если функция SEARCH() возвращает число, это означает, что текст присутствует в ячейке. Если функция возвращает значение ошибки, значит, текст отсутствует.
Excel также предоставляет другие функции для работы с текстом, такие как FIND(), LEN(), REPLACE() и др. Они позволяют выполнять различные операции над текстом, включая замену символов, определение длины текста и поиск позиции символа.
Таким образом, Excel имеет возможность содержать текст в ячейке, а также обрабатывать и извлекать часть текста с помощью соответствующих функций. Это делает Excel удобным инструментом для работы с текстовыми данными в электронных таблицах.
КАК ВЫДЕЛИТЬ ЯЧЕЙКИ В КОТОРЫХ СОДЕРЖИТСЯ НУЖНЫЙ ТЕКСТ // УСЛОВНОЕ ФОРМАТИРОВАНИЕ + ФУНКЦИЯ ПОИСК
Равно ли значение ячейки одному из списка значений? Простая формула Excel
Функция ЕСЛИ в excel пример с текстом
5 Трюков Excel, о которых ты еще не знаешь!
Аналог функции ВПР в Excel ➤ Поиск всех совпадений
Excel если ячейка содержит определенный текст, то..найти задать условие. Если есть искомые слова v.2
Сводные таблицы Excel с нуля до профи за полчаса + Дэшборды! - 1-ое Видео курса \
Как вытащить часть текста из ячейки excel
ТЕСТ! Выберите подарок, а я расскажу что ждет Вас в 2024 году!
Вам также может понравиться:
 КАК СДЕЛАТЬ ССЫЛКУ НА ЭКСЕЛЬ ТАБЛИЦУ В ГУГЛ ДОКС
КАК СДЕЛАТЬ ССЫЛКУ НА ЭКСЕЛЬ ТАБЛИЦУ В ГУГЛ ДОКС ЭКСЕЛЬ ДЛЯ МАК
ЭКСЕЛЬ ДЛЯ МАК ИЗМЕНИТЬ ФОРМАТ ЯЧЕЙКИ В EXCEL
ИЗМЕНИТЬ ФОРМАТ ЯЧЕЙКИ В EXCEL ФОРМУЛА ИПОТЕКИ В EXCEL
ФОРМУЛА ИПОТЕКИ В EXCEL КАК СДЕЛАТЬ ЧТОБЫ ЭКСЕЛЬ ОТКРЫВАЛСЯ В РАЗНЫХ ОКНАХ
КАК СДЕЛАТЬ ЧТОБЫ ЭКСЕЛЬ ОТКРЫВАЛСЯ В РАЗНЫХ ОКНАХ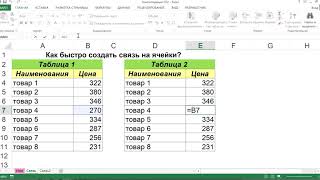 КАК В EXCEL ИЗМЕНИТЬ СВЯЗИ
КАК В EXCEL ИЗМЕНИТЬ СВЯЗИ КАК ЗАКРЕПИТЬ ЗАГОЛОВОК ТАБЛИЦЫ В EXCEL ПРИ ПЕЧАТИ
КАК ЗАКРЕПИТЬ ЗАГОЛОВОК ТАБЛИЦЫ В EXCEL ПРИ ПЕЧАТИ EXCEL УДАЛИТЬ ОТФИЛЬТРОВАННЫЕ СТРОКИ В EXCEL
EXCEL УДАЛИТЬ ОТФИЛЬТРОВАННЫЕ СТРОКИ В EXCEL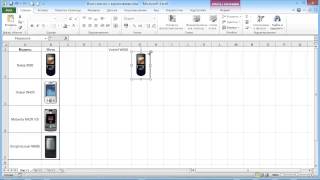 EXCEL КАРТИНКА В ЯЧЕЙКЕ
EXCEL КАРТИНКА В ЯЧЕЙКЕ