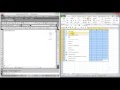
КАК В EXCEL ПОСТРОИТЬ КРИВУЮ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
Кривая нормального распределения является важным инструментом статистического анализа, который может помочь вам понять, как данные распределены в Excel. Эта кривая также известна как кривая Гаусса или колоколообразная кривая, и представляет собой график функции плотности вероятности.
В Excel вы можете построить кривую нормального распределения с помощью центрирования данных вокруг среднего значения и использования стандартного отклонения. Вот шаги, которые вы можете следовать, чтобы построить кривую нормального распределения в Excel:
1. Создайте столбец, содержащий данные, которые вы хотите проанализировать.
2. Вычислите среднее значение вашего набора данных с помощью функции СРЗНАЧ, например, "=СРЗНАЧ(A1:A100)". Здесь A1:A100 - диапазон ячеек, содержащих ваши данные.
3. Вычислите стандартное отклонение с помощью функции СТЬЮДЕВ, например, "=СТЬЮДЕВ(A1:A100)".
4. Создайте диапазон значений "x", на котором вы хотите построить график кривой нормального распределения. Например, от -3 стандартных отклонений до +3 стандартных отклонений вокруг среднего значения.
5. Используйте формулу плотности вероятности нормального распределения для каждого значения "x" с помощью функции СТАНДАРТНОЕ_НОРМАЛЬНОЕ_РАСПРЕДЕЛЕНИЕ, например, "=СТАНДАРТНОЕ_НОРМАЛЬНОЕ_РАСПРЕДЕЛЕНИЕ(x) * стандартное_отклонение + среднее_значение".
6. Постройте график данных, чтобы визуализировать кривую нормального распределения. Вы можете использовать график точек или линейный график для этой цели.
Теперь вы знаете, как построить кривую нормального распределения в Excel и использовать ее для анализа своих данных. Этот инструмент может быть полезным для исследования и представления статистической информации в вашей работе.
Нормальное распределение в Excel
Интервальный вариационный ряд в MS Excel. Гистограмма, полигон, функция распределения
Как проверить гипотезу о нормальном распределении ген. совокупности? Критерий согласия Пирсона
Построение фактического и теоретического кривого распределения в MS EXCEL
Excel Histogram with Normal Distribution Curve
Как построить нормальную кривую? (график плотности и график функции распределения)
Как построить эмпирическую функцию распределения в MS Excel?
Вам также может понравиться:
 КОЛИЧЕСТВО В ЭКСЕЛЬ
КОЛИЧЕСТВО В ЭКСЕЛЬ КАК УБРАТЬ НУЛИ ПОСЛЕ ТОЧКИ В ЭКСЕЛЕ
КАК УБРАТЬ НУЛИ ПОСЛЕ ТОЧКИ В ЭКСЕЛЕ ЛОГИЧЕСКИЕ ФУНКЦИИ В EXCEL ПРИМЕРЫ РЕШЕНИЯ ЗАДАЧ
ЛОГИЧЕСКИЕ ФУНКЦИИ В EXCEL ПРИМЕРЫ РЕШЕНИЯ ЗАДАЧ КАК В EXCEL ИЗМЕНИТЬ ГРАНИЦЫ ГРАФИКА
КАК В EXCEL ИЗМЕНИТЬ ГРАНИЦЫ ГРАФИКА КАК В ЭКСЕЛЬ СТЕПЕНЬ ПОСТАВИТЬ
КАК В ЭКСЕЛЬ СТЕПЕНЬ ПОСТАВИТЬ КАЛЕНДАРЬ В EXCEL СДЕЛАТЬ
КАЛЕНДАРЬ В EXCEL СДЕЛАТЬ КАК СКОПИРОВАТЬ ФОРМУЛУ В EXCEL В ДРУГУЮ ЯЧЕЙКУ БЕЗ ИЗМЕНЕНИЯ
КАК СКОПИРОВАТЬ ФОРМУЛУ В EXCEL В ДРУГУЮ ЯЧЕЙКУ БЕЗ ИЗМЕНЕНИЯ КАК НАЙТИ МЕЖКВАРТИЛЬНЫЙ РАЗМАХ В EXCEL
КАК НАЙТИ МЕЖКВАРТИЛЬНЫЙ РАЗМАХ В EXCEL ПРИБАВИТЬ ПРОЦЕНТ В ЭКСЕЛЬ ФОРМУЛА
ПРИБАВИТЬ ПРОЦЕНТ В ЭКСЕЛЬ ФОРМУЛА