В EXCEL КАК ОТДЕЛИТЬ ТЕКСТ ОТ ЦИФР
В Microsoft Excel есть несколько методов, которые позволяют отделить текст от цифр в ячейках. Это особенно полезно, если вы работаете с данными, где нужно разделить текст и числа для дальнейшей обработки или анализа.
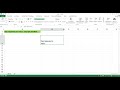
1. Функция ПЛСЧИСЛО: Если текст и числа находятся в одной ячейке, вы можете использовать функцию ПЛСЧИСЛО. Она преобразует текст, содержащий числовое значение, в числовой формат. Вы можете использовать эту функцию следующим образом: =ПЛСЧИСЛО(ячейка).
2. Функции ЛЕВСИМВ и ПРАВСИМВ: Если вам нужно отделить текст и числа, находящиеся в начале или конце ячейки, вы можете использовать функции ЛЕВСИМВ и ПРАВСИМВ. Функция ЛЕВСИМВ возвращает указанное количество символов текста из начала строки, а функция ПРАВСИМВ - из конца строки. Например, чтобы получить только текст из ячейки A1, используйте формулу =ЛЕВСИМВ(A1;ДЛСТР(A1)-ЧИСЛО(ПЛСЧИСЛО(A1))).
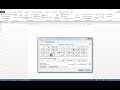
3. Функция ПРЕОБРАЗ: Эта функция помогает преобразовать числа, записанные в виде текста, в числовой формат. Она удаляет все непечатные символы, пробелы и знаки валюты, которые могут мешать преобразованию. Просто примените функцию ПРЕОБРАЗ к ячейке с текстом и числами: =ПРЕОБРАЗ(ячейка;1).
4. Использование формулы РАЗДЕЛИТЬ: Если текст и числа разделены определенным символом, например, запятой или пробелом, вы можете использовать формулу РАЗДЕЛИТЬ. Эта формула разделяет текст на отдельные части и помещает их в отдельные столбцы. Например, чтобы разделить текст и числа, используя запятую в ячейке A1, используйте формулу =РАЗДЕЛИТЬ(A1;", ").
В Microsoft Excel есть еще множество других методов и функций для работы с текстом и числами. Выберите тот, который наиболее удобен для вашей конкретной задачи.
Поиск ключевых слов в тексте (формулами и в Power Query)
5 Трюков Excel, о которых ты еще не знаешь!
Аналог функции ВПР в Excel ➤ Поиск всех совпадений
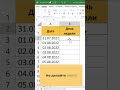
Как отделить текст от цифр? Суммировать цифры в тексте
Отделить текст от цифр в ячейке EXCEL и разбить текст по столбцам
Сводные таблицы Excel с нуля до профи за полчаса + Дэшборды! - 1-ое Видео курса \
Как извлечь только цифры или текст из ячейки. 2й способ. Помощь по гугл таблицам
Сравнение двух списков в Excel (Различия \u0026 Сходства)
Вам также может понравиться:
 КАК ОТКРЫТЬ ФАЙЛ XLSX В EXCEL 2003
КАК ОТКРЫТЬ ФАЙЛ XLSX В EXCEL 2003 EXCEL ДОБАВИТЬ СТРОКУ
EXCEL ДОБАВИТЬ СТРОКУ КАК В EXCEL ПРИСВОИТЬ ТЕКСТУ ЧИСЛОВОЕ ЗНАЧЕНИЕ
КАК В EXCEL ПРИСВОИТЬ ТЕКСТУ ЧИСЛОВОЕ ЗНАЧЕНИЕ КАК СОЗДАТЬ ЭКЗАМЕНАЦИОННУЮ ВЕДОМОСТЬ В EXCEL
КАК СОЗДАТЬ ЭКЗАМЕНАЦИОННУЮ ВЕДОМОСТЬ В EXCEL ЗАВИС ЭКСЕЛЬ КАК СОХРАНИТЬ ДАННЫЕ
ЗАВИС ЭКСЕЛЬ КАК СОХРАНИТЬ ДАННЫЕ КАК ПЕРЕНЕСТИ ТЕКСТ С ОДНОЙ СТРАНИЦЫ НА ДРУГУЮ В ЭКСЕЛЕ
КАК ПЕРЕНЕСТИ ТЕКСТ С ОДНОЙ СТРАНИЦЫ НА ДРУГУЮ В ЭКСЕЛЕ КАК ДОБАВИТЬ МОДУЛЬ В ЭКСЕЛЬ
КАК ДОБАВИТЬ МОДУЛЬ В ЭКСЕЛЬ EXCEL КАК РАЗДЕЛИТЬ СТОЛБЕЦ НА ДВА В
EXCEL КАК РАЗДЕЛИТЬ СТОЛБЕЦ НА ДВА В РАБОТА В ЭКСЕЛЬ
РАБОТА В ЭКСЕЛЬ