В EXCEL УДАЛИТЬ ПОВТОРЫ В
В Excel удалить повторы в - одна из самых полезных функций при работе с данными. Когда у вас есть большой набор информации, включающий дубликаты, удаление повторов может помочь вам создать более чистую и удобную таблицу.
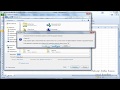
Для удаления повторов в Excel можно воспользоваться инструментами фильтрации и удаления дубликатов. Вот несколько шагов, которые помогут вам выполнить это действие:
- Выделите диапазон ячеек, в которых находятся данные, включая заголовки столбцов.
- На вкладке "Данные" найдите группу инструментов "Удаление дубликатов" и выберите нужную опцию в зависимости от вашей ситуации.
- После этого появится диалоговое окно с параметрами удаления дубликатов. Установите необходимые опции и нажмите "ОК".
- Excel удалит все повторы в указанном диапазоне ячеек, оставляя только уникальные значения.
Это довольно простой способ удаления повторов в Excel, который может сэкономить ваше время и помочь в упорядочении данных.
Надеемся, что эта информация оказалась полезной для вас. Удачного использования Excel!
Повторяющиеся значения в Excel: найти, выделить и удалить дубликаты
5 Трюков Excel, о которых ты еще не знаешь!
Умная таблица в Excel ➤ Секреты эффективной работы
Повторяющиеся значения в Excel — найти, выделить или удалить дубликаты в Excel
Как найти и удалить дубликаты в EXCEL: в таблице , в двух списках. (Рассмотрено 4 быстрых способа)
Функция ВПР в Excel. от А до Я
Как объединить две таблицы и более в одну? / Объединение нескольких таблиц в Excel
Вам также может понравиться:
 КАК В EXCEL ВЫЧИТАТЬ ДАТЫ
КАК В EXCEL ВЫЧИТАТЬ ДАТЫ КАК ВЫЗВАТЬ СПРАВКУ EXCEL
КАК ВЫЗВАТЬ СПРАВКУ EXCEL СЛОЖЕНИЕ СТРОК В EXCEL
СЛОЖЕНИЕ СТРОК В EXCEL КАК ПЕРЕИМЕНОВАТЬ СТОЛБЦЫ В СВОДНОЙ ТАБЛИЦЕ EXCEL
КАК ПЕРЕИМЕНОВАТЬ СТОЛБЦЫ В СВОДНОЙ ТАБЛИЦЕ EXCEL КАК СДЕЛАТЬ ФОН В ЭКСЕЛЬ
КАК СДЕЛАТЬ ФОН В ЭКСЕЛЬ КАК УДАЛИТЬ ВЫДЕЛЕННЫЕ ЦВЕТОМ ЯЧЕЙКИ В EXCEL
КАК УДАЛИТЬ ВЫДЕЛЕННЫЕ ЦВЕТОМ ЯЧЕЙКИ В EXCEL КАКУЮ КОМАНДУ ЭКСЕЛЬ СЛЕДУЕТ ИСПОЛЬЗОВАТЬ ЧТОБЫ ОТРЕДАКТИРОВАТЬ РАНЕЕ СОЗДАННЫЙ ДОКУМЕНТ
КАКУЮ КОМАНДУ ЭКСЕЛЬ СЛЕДУЕТ ИСПОЛЬЗОВАТЬ ЧТОБЫ ОТРЕДАКТИРОВАТЬ РАНЕЕ СОЗДАННЫЙ ДОКУМЕНТ КАК В ЭКСЕЛЬ ПОСЧИТАТЬ СУММУ
КАК В ЭКСЕЛЬ ПОСЧИТАТЬ СУММУ КАК В EXCEL СЛОЖИТЬ ТЕКСТОВЫЕ ЯЧЕЙКИ В
КАК В EXCEL СЛОЖИТЬ ТЕКСТОВЫЕ ЯЧЕЙКИ В