ОБЪЕДИНИТЬ ПОВТОРЯЮЩИЕСЯ ЯЧЕЙКИ В EXCEL
В Microsoft Excel есть возможность объединить повторяющиеся ячейки для упрощения работы с данными. Эта функция позволяет объединять содержимое ячеек с одинаковым значением в одну ячейку с кратким описанием.
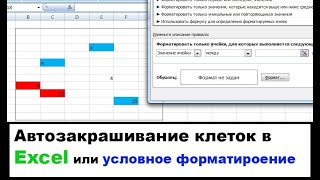
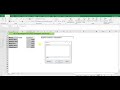
Чтобы объединить повторяющиеся ячейки в Excel, выполните следующие шаги:
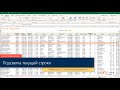
- Выделите диапазон ячеек, которые нужно объединить.
- На панели инструментов выберите вкладку "Слияние и центрирование".
- Нажмите на кнопку "Объединить и центрировать".
После выполнения этих шагов все ячейки с одинаковым значением будут объединены в одну ячейку.
Объединение повторяющихся ячеек может быть полезным при работе с большими таблицами или при необходимости подготовить отчеты и сводные таблицы. Оно помогает сделать данные более читабельными и компактными, что упрощает их анализ и визуализацию.
Используйте функцию объединения повторяющихся ячеек в Excel, чтобы сэкономить время и сделать свою работу более продуктивной!
КАК БЫСТРО ПОСЧИТАТЬ ДУБЛИКАТЫ В ТАБЛИЦЕ EXCEL
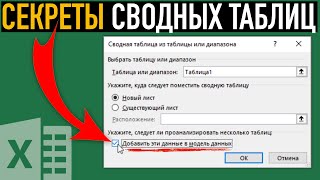
Создание сводной таблицы по данным с разных листов ➤ Модель данных в Excel
Аналог функции ВПР в Excel ➤ Поиск всех совпадений
Как объединить ячейки в excel ✅ объединить текст в ячейках excel ✅ объединить данные ячейки в эксель
Умная таблица в Excel ➤ Секреты эффективной работы
#28 Как БЫСТРО просуммировать повторяющиеся строки
Как в Excel объединить одинаковые и разъединить объединенные ячейки
#14 Как просуммировать повторяющиеся строки в таблице
Повторяющиеся значения в Excel: найти, выделить и удалить дубликаты
Вам также может понравиться: